README
KServe


![]()
KServe is a standardized distributed generative and predictive AI inference platform for scalable, multi-framework deployment on Kubernetes.
KServe is being used by many organizations and is a Cloud Native Computing Foundation (CNCF) incubating project.
For more details, visit the KServe website.
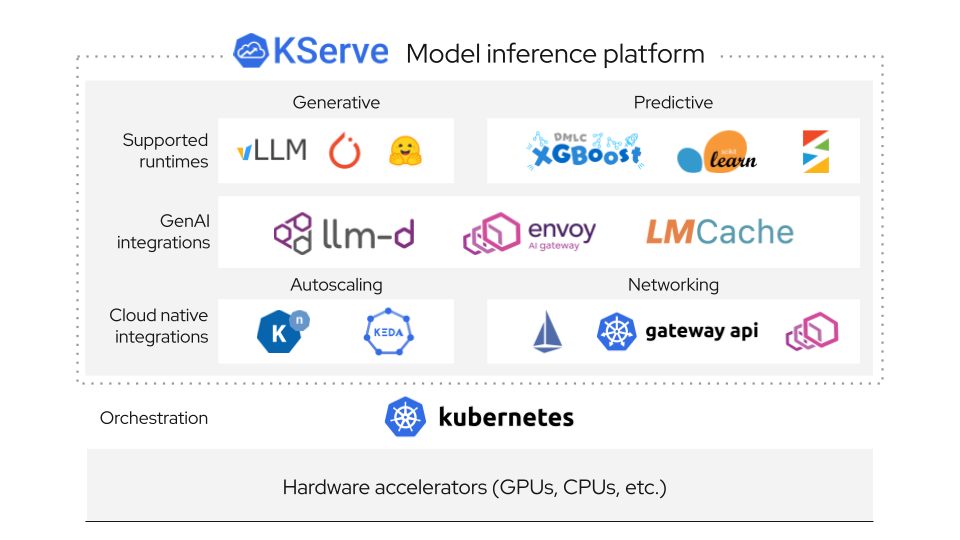
Why KServe?
Single platform that unifies Generative and Predictive AI inference on Kubernetes. Simple enough for quick deployments, yet powerful enough to handle enterprise-scale AI workloads with advanced features.
Features
Generative AI
- 🧮 Optimized Backends: Support for vLLM and llm-d for optimized performance for serving LLMs
- 📌 Standardization: OpenAI-compatible inference protocol for seamless integration with LLMs
- 🚅 GPU Acceleration: High-performance serving with GPU support and optimized memory management for large models
- 💾 Model Caching: Intelligent model caching to reduce loading times and improve response latency for frequently used models
- 🗂️ KV Cache Offloading: Advanced memory management with KV cache offloading to CPU/disk for handling longer sequences efficiently
- 📈 Autoscaling: Request-based autoscaling capabilities optimized for generative workload patterns